Cryptographic Toolkit
This suite proposes a solution for selective disclosure of issuer attested claims (verifiable credentials).
Unlike previous solutions such as CL Signatures or BBS+ Signatures 2020, this approach does not rely on Zero Knowledge Proofs, instead it relies on Merkle Proofs.
Merkle Proofs
A key advantage of using merkle proofs is proving set membership by only relying on cryptographic hash functions.
Because a verifier will learn some information about undislosed set members when verifying a proof for disclosed ones, this solution does leak some information. The information a verifier learns is the path from a leaf to a merkle root, which proves a member exists in the set, but this path is built from hashes of members of the set the prover may not be dislosing.
A robust summary of merkle proofs is beyond the scope of this specification. The proof of concept we build relies on this implementation. The diagram below is from the wikipedia page on merkle trees.
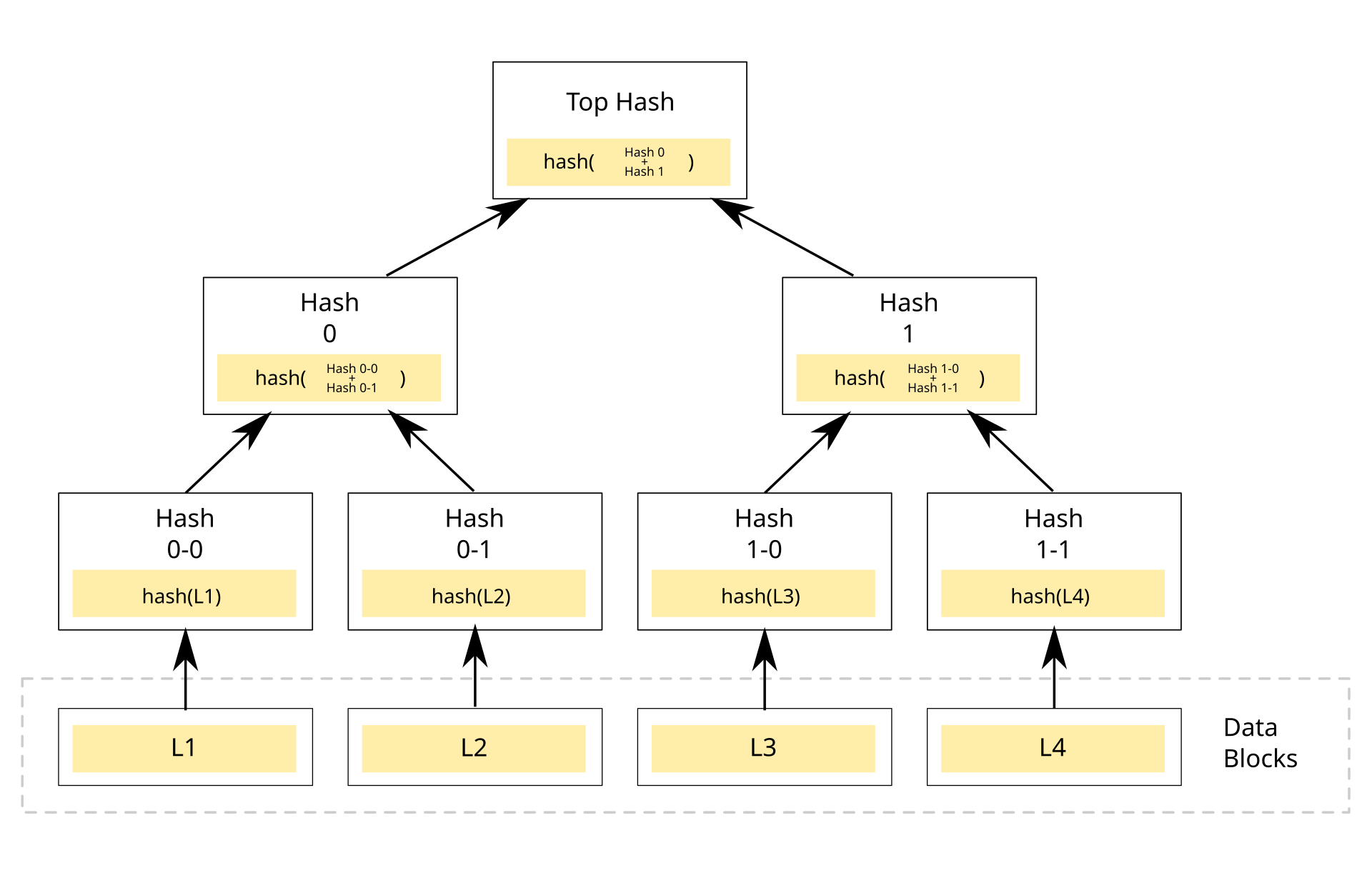
Json Web Signatures
The most popular solution to encoding digital signatures that rely on standard cryptography in JSON is [[RFC7515]].
A robust summary of Json Web Signatures is beyond the scope of this specification.
By using a standard digital signature approach to sign the
merkle root, a holder can then disclose
messages and proofs, which can be verified
as originating from the issuer who produced the signature using their
private key.
An advantage of building selective disclosure proofs on top of JWS is that keys already in use for single message proofs can be used with multi message selective dislosure proofs.
[[RFC7515]] has been implemented in many languages. JWS and JWT are used as the foundation of most modern identity assurance systems.
Compression
One of the disadvantages of merkle proofs is their size.
As you can see in the merkle tree diagram, the size of a single set membership proof is O(log n). Depending on the size of the associated hashes, this can make sparse disclosures of set members (revealing all but a few members) very expensive in proof size.
Luckily each membership proof share common nodes in the tree, allowing for compression algorithms to provide significant advantage when disclosing most of the members of a set.
In our proof of concept we use this compression implementation, which is essentially the same as gzip.
Compressed encoding of merkle proofs is an area where better standards are needed. The solution we have used is subject to BREAKING CHANGES.