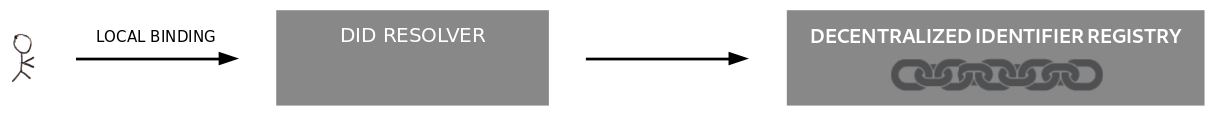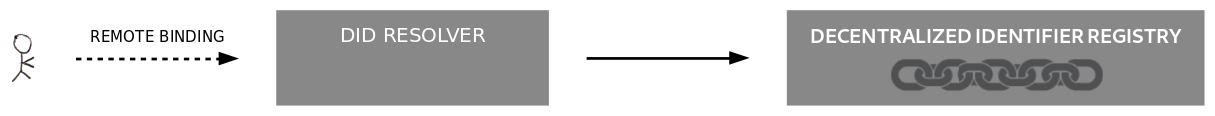Decentralized identifiers (DIDs) are a new type of identifier for
verifiable, "self-sovereign" digital identity. DIDs are fully under the
control of the DID controller, independent from any centralized registry,
identity provider, or certificate authority. DIDs resolve to DID
Documents — simple documents that describe how to use that specific DID.
This document specifies the algorithms and guidelines for resolving DIDs
and dereferencing DID URLs.
Portions of the work on this specification have been funded by the
United States Department of Homeland Security's Science and Technology
Directorate under contracts HSHQDC-17-C-00019. The content of this
specification does not necessarily reflect the position or the policy of
the U.S. Government and no official endorsement should be inferred.
Work on this specification has also been supported by the Rebooting the
Web of Trust community facilitated by Christopher Allen, Shannon
Appelcline, Kiara Robles, Brian Weller, Betty Dhamers, Kaliya Young, Kim
Hamilton Duffy, Manu Sporny, Drummond Reed, Joe Andrieu, and Heather
Vescent.
Introduction
DID resolution is the process of obtaining a DID document for a given DID. This is one
of four required operations that can be performed on any DID ("Read"; the other ones being "Create", "Update",
and "Deactivate"). The details of these operations differ depending on the DID method.
Building on top of DID resolution, DID URL dereferencing is the process of retrieving a representation
of a resource for a given DID URL. Software and/or hardware that is able to execute these processes is called
a DID resolver.
This
specification defines common
requirements, algorithms including their inputs and results, architectural options, and various considerations for the
DID resolution and DID URL dereferencing processes.
Note that while this specification defines some base-level functionality for DID resolution, the actual steps
required to communicate with a DID's verifiable data registry are defined by the applicable
DID method specification.
The difference between "resolving" a DID and "dereferencing" a DID URL
is being thoroughly discussed by the community. For example, see
this comment.
A data structure that represents the result of the DID resolution algorithm.
May contain a DID document. See Section .
DID URL
As defined in [[DID-CORE]].
DID URL dereferencing
As defined in [[DID-CORE]]. See Section .
DID URL dereferencer
As defined in [[DID-CORE]].
DID URL dereferencing result
A data structure that represents the result of the DID URL dereferencing algorithm.
May contain a DID document or other content. See Section .
local binding
A binding where the client invokes a DID resolver that runs on the same network host, e.g., via a local command line tool or library API.
In this case, the DID resolver is sometimes also called a "local DID resolver".
See Section .
An algorithm that takes a DID URL and a service, and constructs
a service endpoint URL See Section .
unverifiable read
A low confidence implementation of a DID method's "Read" operation between the
DID resolver and the verifiable data registry, to obtain the DID document.
There is no guarantee about the integrity and correctness of the result. See Section .
verifiable data registry
As defined in [[DID-CORE]].
verifiable read
A high confidence implementation of a DID method's "Read" operation between the
DID resolver and the verifiable data registry, to obtain the DID document.
There are guarantees about the integrity and correctness of the result to the extent possible under the applicable DID method.
See Section .
Resolving a DID
This section defines an algorithm for DID resolution, based on the abstract functions resolve()
and resolveRepresentation() as defined in section DID Resolution in [[DID-CORE]]:
Determine whether the DID method of the input DID is supported by the DID resolver
that implements this algorithm. If not, the DID resolver MUST return the following result:
There is discussion how a DID that has been
deactivated should be treated during the DID resolution
process.
Specify how signatures/proofs on a DID document should be verified during the
DID resolution process.
Should we define functionality that enables discovery of the list of DID methods or other
capabilities that are supported by a DID resolver? Or is this implementation-specific and out-of-scope
for this spec? For example, see here and
here.
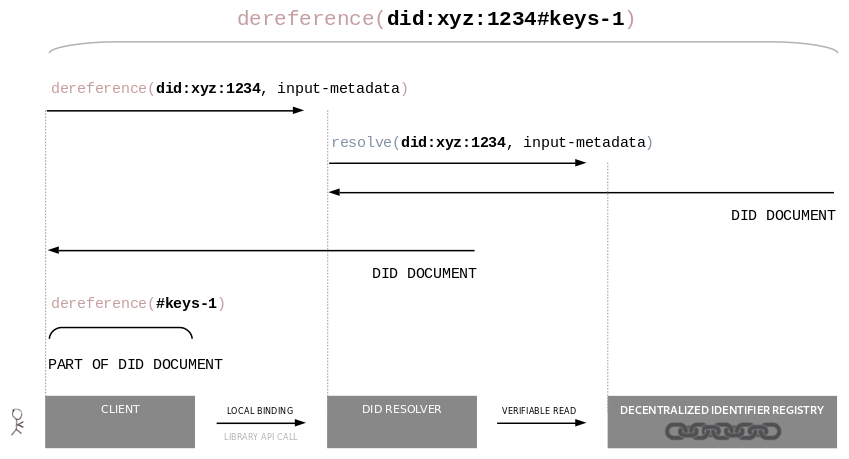
The following DID URL dereferencing algorithm MUST be implemented by a conformant DID resolver.
In accordance with [[RFC3986]], it consists of the following steps: Resolving the DID, dereferencing the primary
resource, and dereferencing the secondary resource (only if the input DID URL contains a DID fragment:
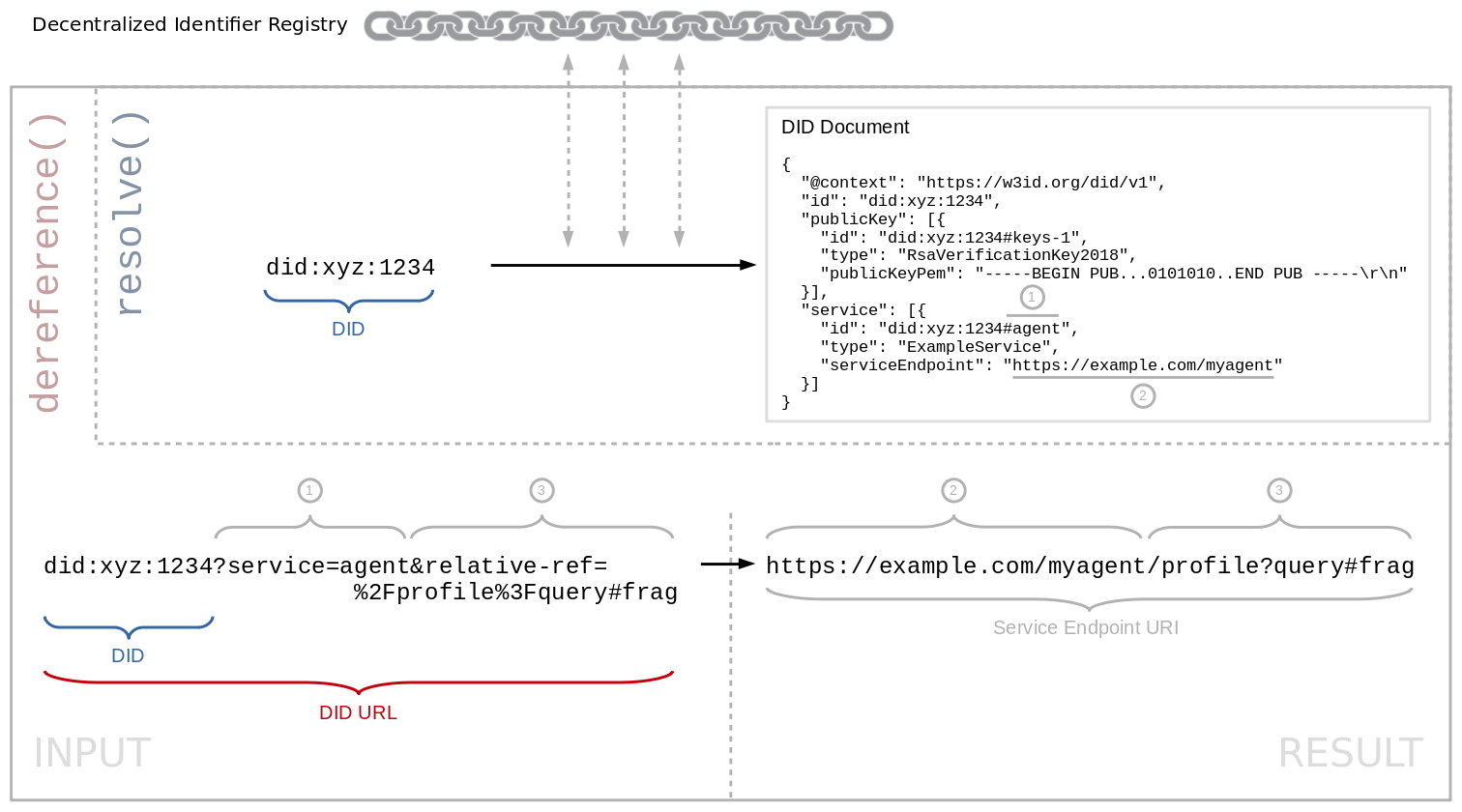
Obtain the DID document for the input DID by executing the
DID resolution algorithm as defined in . All
DID parameters of the input DID URL MUST be passed as resolution options to the DID
Resolution algorithm. If the input DID does not exist, return a null result.
Otherwise, the result is called the resolved DID document.
If present, separate the DID fragment from the input DID URL. Execute the algorithm for
, with the input DID URL adjusted
accordingly.
If the original input DID URL contained a DID fragment, execute the algorithm for
.
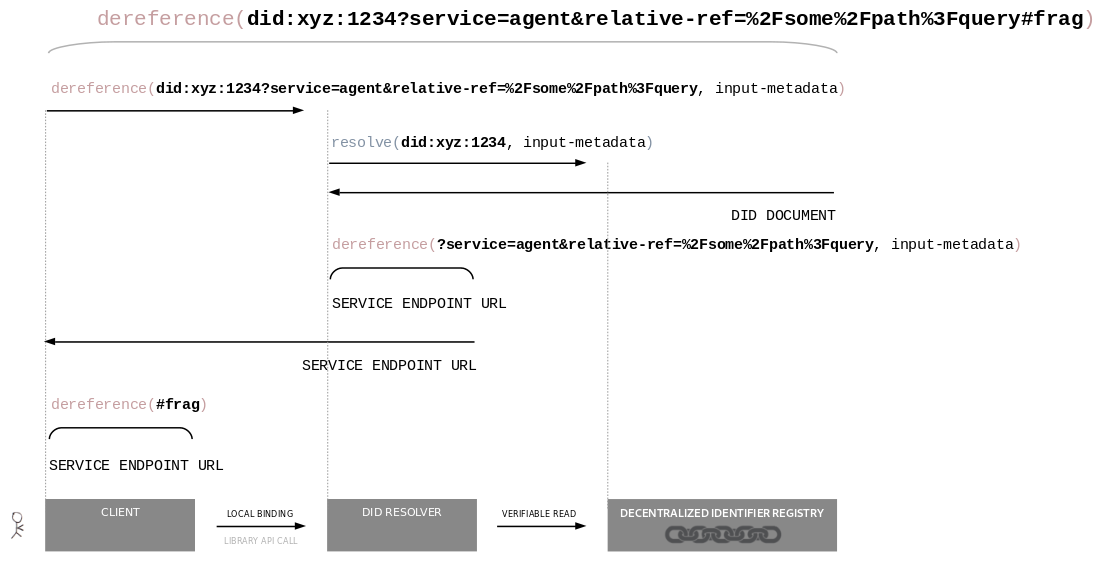
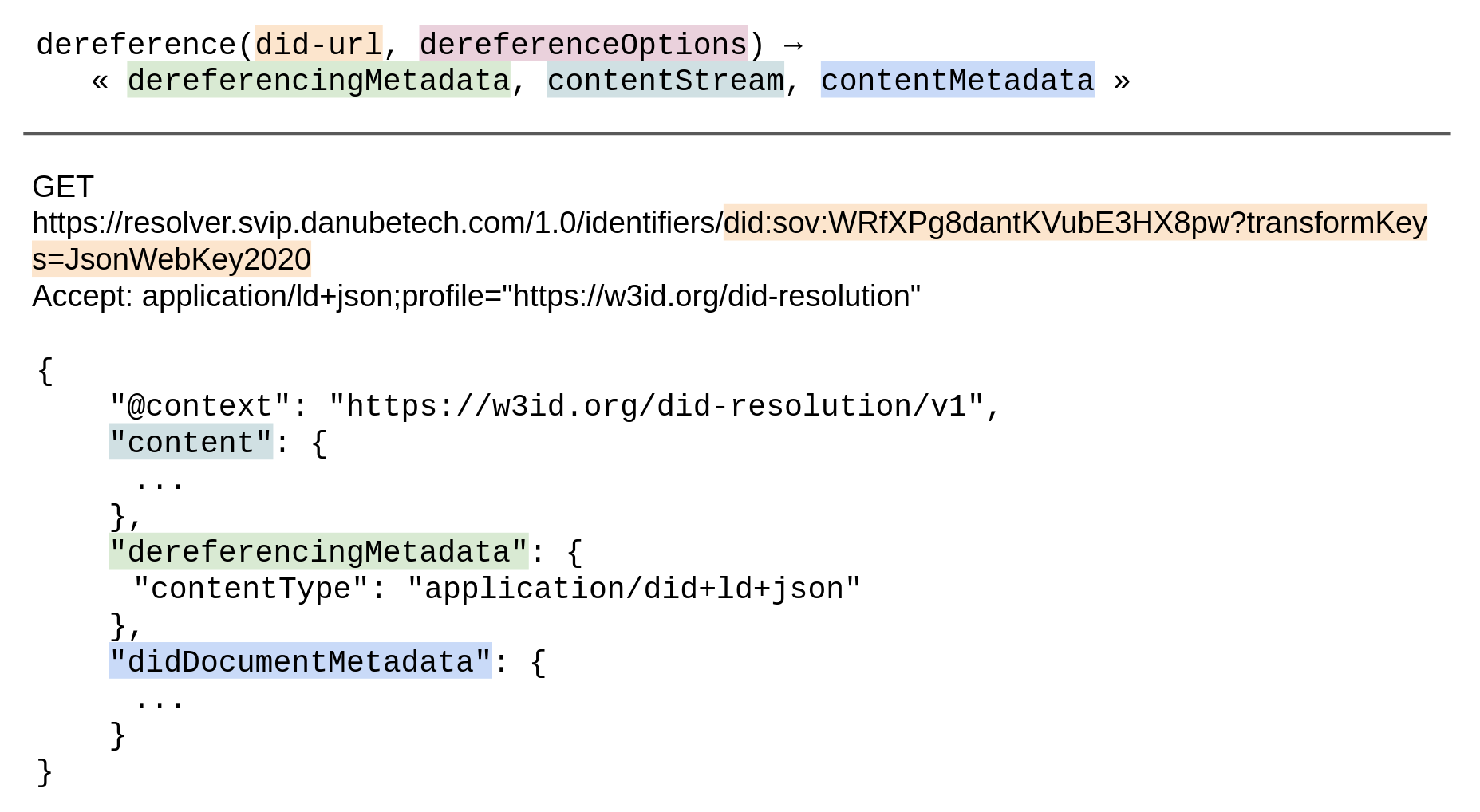
Dereferencing the Primary Resource
If the input DID URL contains the
DID parameterservice and optionally the relativeRef DID parameter:
From the resolved DID document, select the
service endpoint whose id
property contains a fragment which matches the value of the service DID parameter of the
input DID URL. This is called the input service endpoint.
There have been discussions whether in addition to the DID parameter service,
there could also be a DID parameter serviceType to select services based
on their type rather than ID.
See
comments by Dave Longley about `serviceType`.
The applicable DID method MAY specify how to dereference
the input DID URL.
The client MAY be able to dereference the input DID URL
in an application-specific way.
If neither this algorithm, nor the applicable DID method, nor the client
is able to dereference the input DID URL, return the following result:
dereferencingMetadata: «[ "error" → "notFound" ]»
contentStream: null
contentMetadata: «[ ]»
Dereferencing the Secondary Resource
If the input DID URL contains a DID fragment,
then dereferencing of the secondary resource identified by the URL is dependent not on the URI scheme, but
on the media type ([[RFC2046]]) of the primary resource, i.e., on the result of
.
If the result of is a resolved DID document
with media type application/did+ld+json, and the input DID URL contains a
DID fragment:
did:example:1234#keys-1
From the resolved DID document, select the JSON-LD object whose id
property matches the input DID URL, e.g., a public key or service endpoint in the
DID document. This is called the output resource.
When selecting the JSON-LD object from the DID document, the absolute
DID URL used to identify a graph node MUST be unique and present only once in the
DID document. If the identifier of the graph node is not unique,
including if a relative or base IRI mapped to an absolute IRI collides with
a different graph node's absolute IRI, then an error MUST be thrown.
Return the output resource.
Mention relative IRIs and that the DID itself is considered the base IRI for
the JSON-LD parser. Mention potential attack vector if @base is injected into the
DID document.
Also see this discussion
on fully qualified DID URLs as the value of the id field.
This use of the DID fragment is consistent with the definition of the fragment identifier in
[[RFC3986]]. It identifies a secondary resource which is a subset of the primary resource
(the DID document).
This use of the DID fragment is furthermore consistent with the concept of Hash URIs
for the Semantic Web [[COOL-URIS]].
Perhaps we can find a good reference somewhere from RDF, JSON-LD or Solid specifications that defines
clearly the ability to use the fragment for identifying a specific resource in an RDF document.
This behavior of the DID fragment is analogous to the handling of a fragment in an HTTP URL in the
case when dereferencing it returns an HTTP 3xx (Redirection) response with a
Location header (see section 7.1.2 of [[RFC7231]].
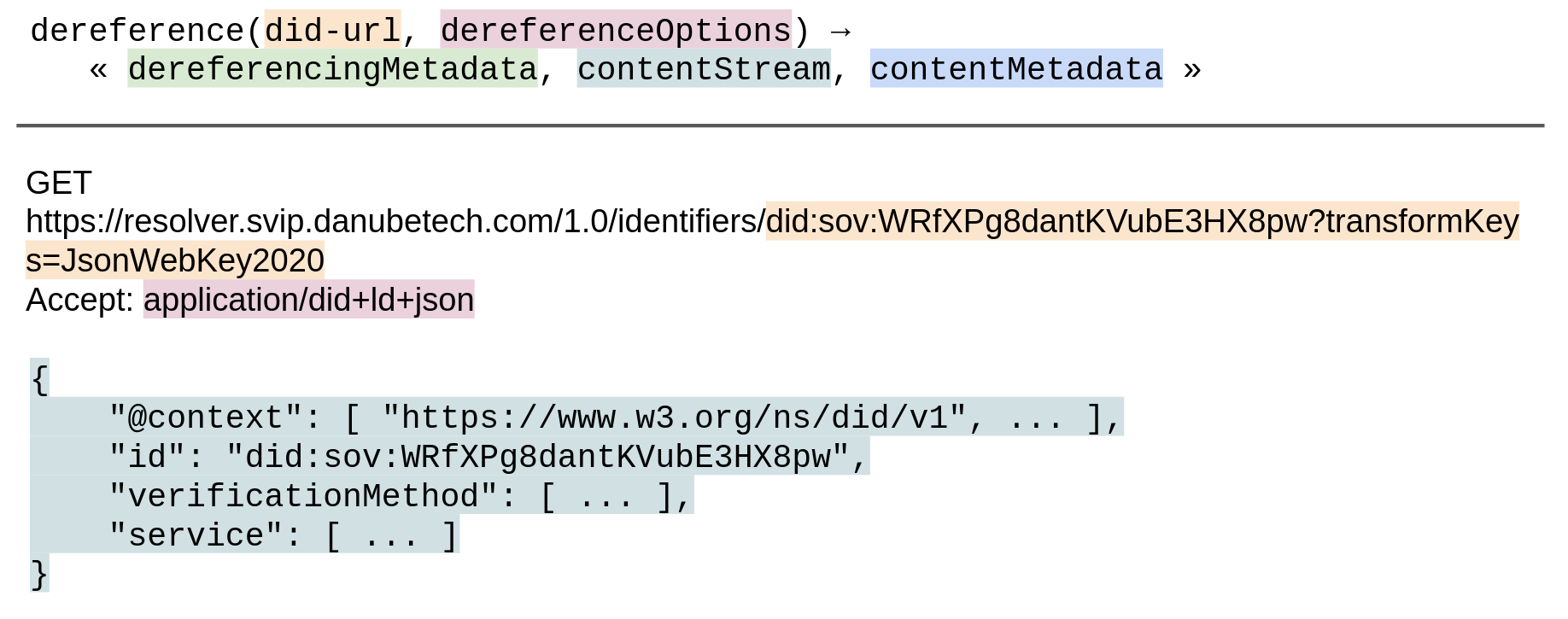
Otherwise, dereference the secondary resource as defined by the media type ([[RFC2046]]) of the primary resource.
Dereferencing a DID URL to a service endpoint URL.
Change the diagram and/or examples to make them consistent.
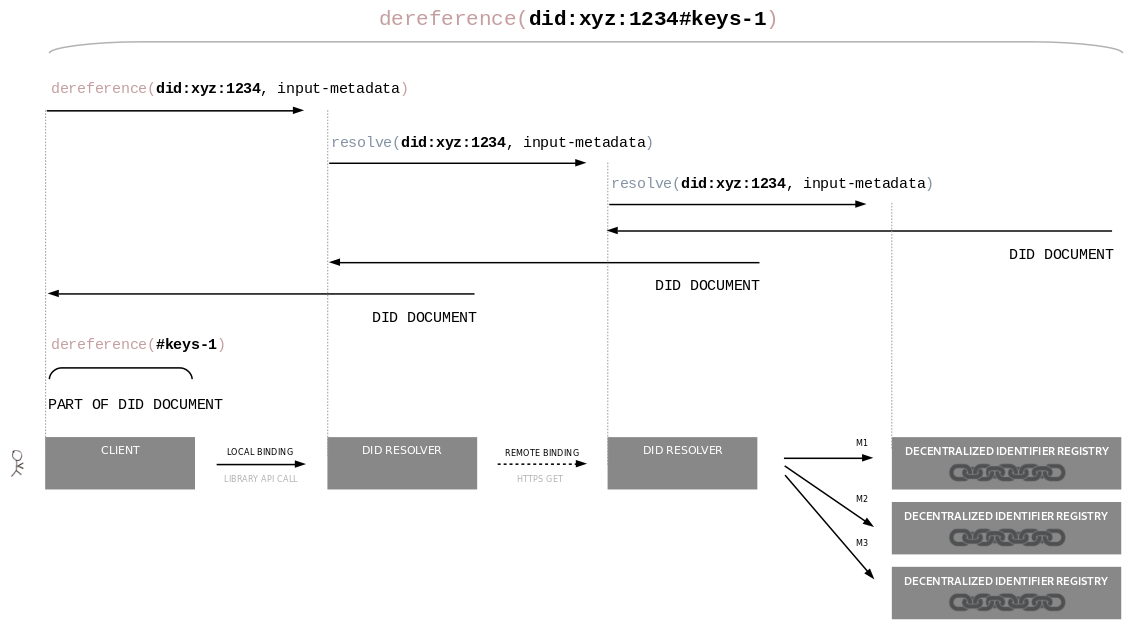
DID Resolution Architectures
TODO: Describe how DID resolvers are implemented and used, describe the relevance
of DID methods.
Explain the difference between "method architectures" and "resolver architectures".
... interaction with a remote network is required during execution of the "Read" operation.
... an actual DID document is stored in plain-text on a verifiable data registry,
or that the DID document can simply be retrieved via a standard protocol such as HTTP(S).
While some DID methods may define their "Read" operation this way, others may
define more complex multi-step processes that involve on-the-fly construction of a "virtual" DID document.
As an example, mention what it means to "resolve" peer/off-ledger/microledger/edgechain DIDs (for instance, see
[[DID-PEER]] and
here).
As an example, mention what it means to "resolve" DIDs that are simply wrapped public keys (for instance, see
[[DID-KEY]] and
here).
A verifiable read maximizes confidence in the integrity and correctness of the result of the "Read" operation ‐ to the extent
possible under the applicable DID method. It can be implemented in a variety of ways, for example:
A "Read" operation may be considered "Verifiable" if access to the verifiable data registry is
possible via a local, trusted network host. In the case of blockchain-based DID methods, a blockchain full node
may be run on a local network host in order to implement a verifiable read.
The DID resolver may be remotely connected to the verifiable data registry but have some method
to verify the contents of the response of the "Read" operation. In the case of blockchain-based DID methods, even if
direct access to a blockchain full node is not available, a verifiable read may still be possible by running a light client that
processes metadata to verify that the result of the "Read" operation hasn't been tampered with.
A verifiable read may be implemented if access to the verifiable data registry happens via a remote
network host that is considered trusted because it is run on a personal device in the home and accessed via
a secure channel.
An unverifiable read does not have such guarantees and is therefore less desirable, for example:
A "Read" operation may be considered "Unverifiable" if access to the verifiable data registry happens
via a remote, untrusted intermediary. In the case of blockchain-based DID methods, a remote blockchain explorer API
operated by an third party may be used to look up data from the blockchain.
Whether or not a verifiable read is possible depends not only on a DID method itself, but also on the way how
a DID resolver implements it. DID methods MAY define multiple different ways of implementing their "Read"
operation(s) and SHOULD offer guidance on how to implement a verifiable read in at least one way.
The guarantees associated with a verifiable read are still always limited by the architectures, protocols, cryptography,
and other aspects of the underlying verifiable data registry. The strongest forms of verifiable read
implementations are considered those that do not require any interaction with a remote network at all (for example, see
[[DID-KEY]]), or that minimize dependencies on specific network infrastructure and reduce the "root of trust"
to proven entropy and cryptography alone (for example, see [[KERI]]).
TODO: Describe how a client can potentially verify the result of a "Read" operation independently even if it does
not trust the DID resolver (e.g., using state proofs).
TODO: Discuss DID resolution in constrained user agents such as mobile apps and browsers.
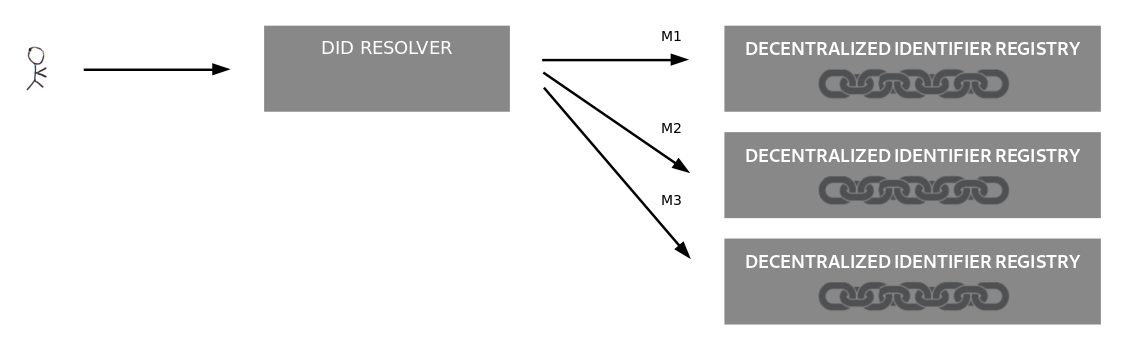
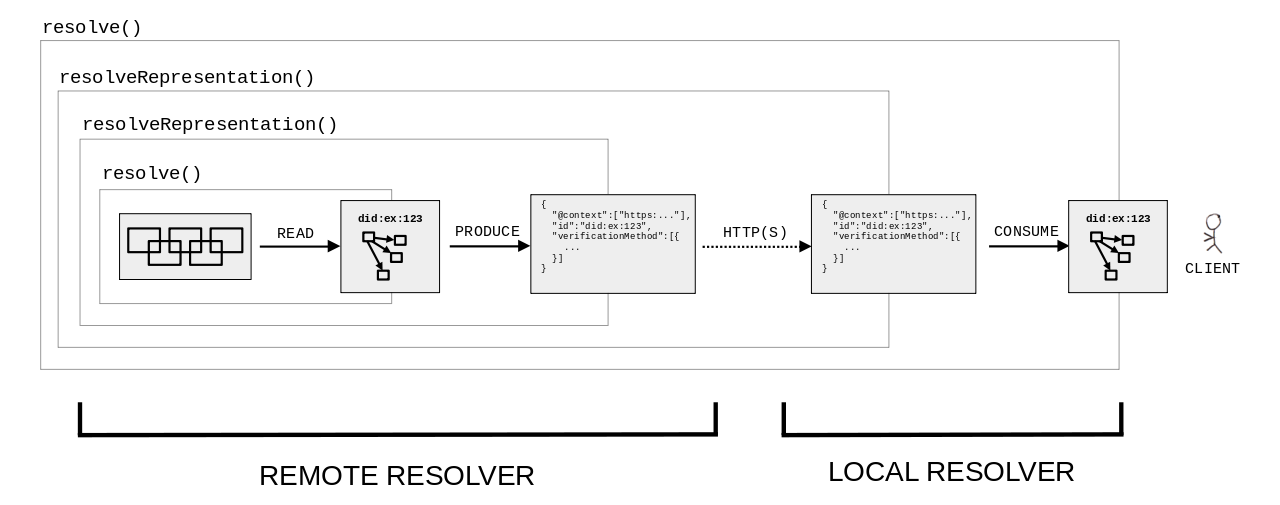
The following diagram shows how the resolve() and resolveRepresentation() functions
use production and consumption rules of DID document representation can apply in an architecture that involves
both a local resolver and a remote resolver.
Production and consumption in an architecture that involves both
a local and a remote DID resolver.
This is similar to a "stub resolver" invoking a "recursive resolver" in DNS architecture, although
the concepts are not entirely comparable (DNS Resolution uses a single concrete protocol, whereas DID resolution
is an abstract function realized by different DID methods and different bindings).
This is a metadata structure (see section Metadata Structure
in [[DID-CORE]]) that contains metadata about a DID Document.
This metadata typically does not change between invocations of the DID Resolution function unless the DID document changes, as it represents data about the DID document.
For certain data, it may be debatable whether it should be part of the DID document
(i.e., data that describes the DID Subject), or whether it is metadata (i.e., data about the DID document or about
the DID resolution process). For example the URL of the "Continuation DID document" in the BTCR method.
This metadata typically changes between invocations of the DID URL Dereferencing functions as it represents data about the dereferencing process itself.
Add more details how DID URL dereferencing metadata works.
This is a metadata structure (see section Metadata Structure
in [[DID-CORE]]) that contains metadata about the content.
This metadata typically does not change between invocations of the DID URL Dereferencing function unless the content changes, as it represents data about the content.
Add more details how content metadata works.
Errors
invalidDid
If an invalid DID is detected during DID Resolution,
the value of the DID Resolution Metadata error property MUST be invalidDid
as defined in section DID Resolution Metadata in [[DID-CORE]].
If a DID document representation is not supported during DID Resolution or DID URL dereferencing,
the value of the DID Resolution Metadata error property MUST be representationNotSupported as
defined in section DID Resolution Metadata in [[DID-CORE]].
methodNotSupported
If a DID method is not supported during DID Resolution or DID URL dereferencing,
the value of the DID Resolution or DID URL Dereferencing Metadata error property MUST be methodNotSupported.
internalError
When an unexpected error occurs during DID Resolution or DID URL dereferencing,
the value of the DID Resolution or DID URL Dereferencing Metadata error property MUST be internalError.
invalidPublicKey
If an invalid public key value is detected during DID Resolution or DID URL dereferencing,
the value of the DID Resolution or DID URL Dereferencing Metadata error property MUST be invalidPublicKey.
invalidPublicKeyLength
If the byte length of rawPublicKeyBytes does not match the expected public key length for the associated multicodecValue during DID Resolution or DID URL dereferencing,
the value of the DID Resolution or DID URL Dereferencing Metadata error property MUST be invalidPublicKeyLength.
invalidPublicKeyType
If an invalid public key type is detected during DID Resolution or DID URL dereferencing,
the value of the DID Resolution or DID URL Dereferencing Metadata error property MUST be invalidPublicKeyType.
unsupportedPublicKeyType
If an unsupported public key type is detected during DID Resolution or DID URL dereferencing,
the value of the DID Resolution or DID URL Dereferencing Metadata error property MUST be unsupportedPublicKeyType.
Bindings
This section defines bindings for the abstract algorithms in sections and
.
If the output of the DID URL dereferencing function contains the dereferencingMetadata property error,
then the HTTP response status code MUST be set to the value that corresponds to the value of the error property,
according to the following table:
error
HTTP status code
invalidDid
400
invalidDidUrl
400
notFound
404
representationNotSupported
406
methodNotSupported
501
internalError
500
(any other value)
500
If the output of the DID URL dereferencing function contains the didDocumentMetadata property deactivated with value true:
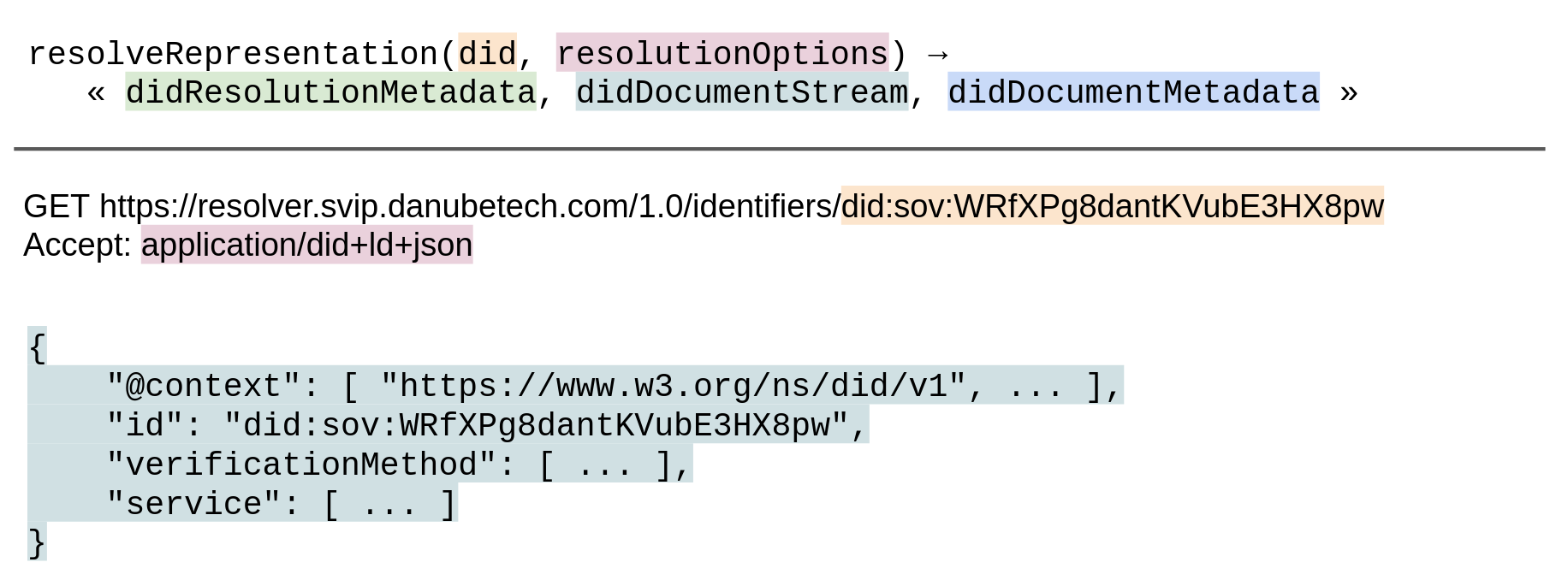
If the value of the Accept HTTP header is absent or `application/did+ld+json` (or other media type of a conformant representation of a DID document):
The HTTP response status code MUST be 200.
The HTTP response MUST contain a Content-Type header. The
value of this header MUST be `application/did+ld+json` (or other media type of a conformant representation of a DID document).
The HTTP response body MUST contain the didDocumentStream, in the representation corresponding to the Accept HTTP header.
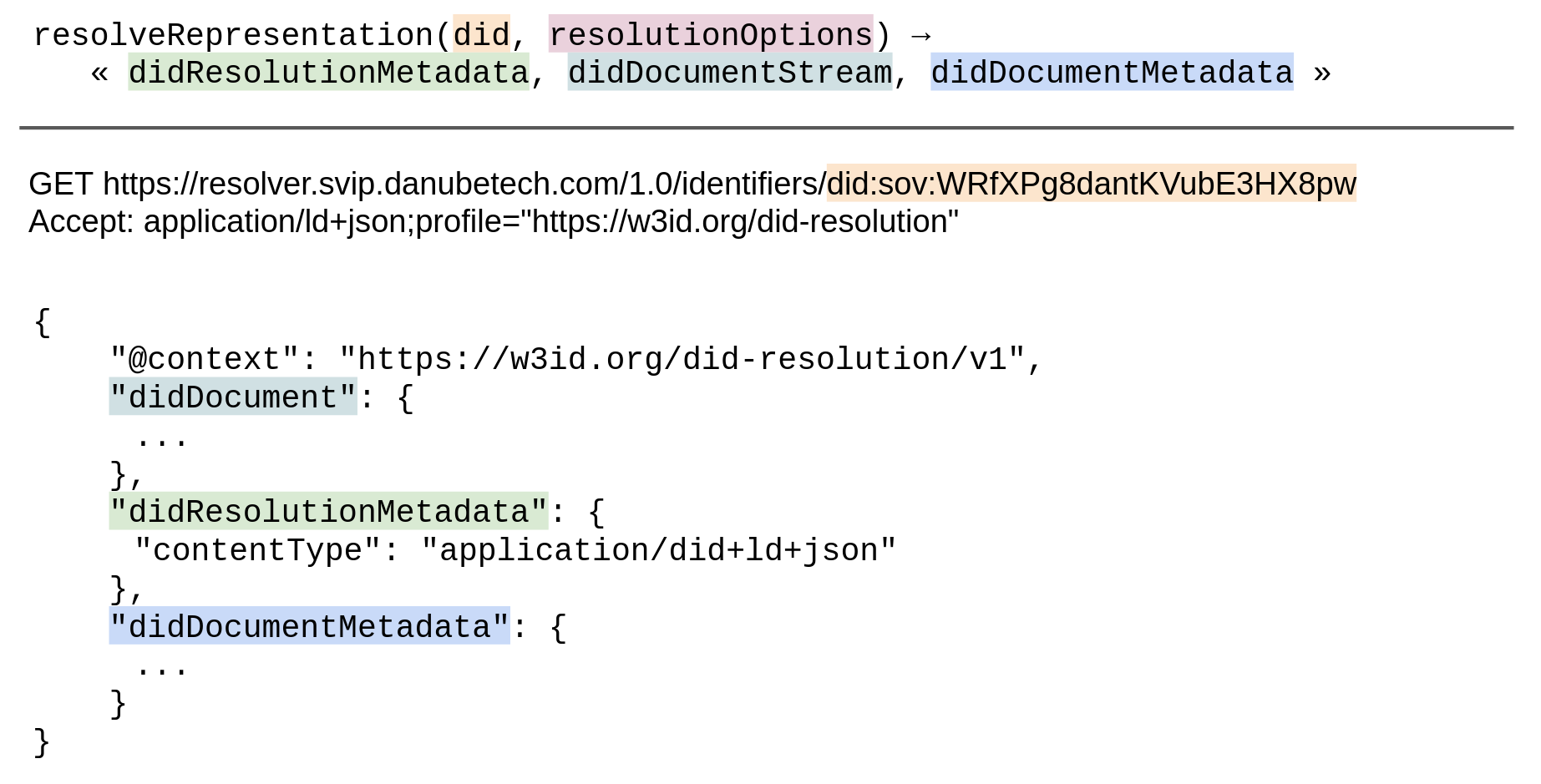
If the value of the Accept HTTP header is `application/ld+json;profile="https://w3id.org/did-resolution"`:
Produce a DID resolution result (see (see ) and populate it with the didDocumentStream,
didResolutionMetadata, and didDocumentMetadata that are the output of the
DID resolution function.
The HTTP response status code MUST be 200.
The HTTP response MUST contain a Content-Type header. The
value of this header MUST be `application/ld+json;profile="https://w3id.org/did-resolution"`.
How should Accept and Content-Type HTTP headers be used? How are
the resolve() and resolveRepresentation() functions called? See
this issue for a discussion.
Are two separate HTTP(S) endpoints required/allowed for the resolve() and
dereference() functions, or can/must a single HTTP(S) endpoint be used?
DID Resolution Examples
Given the following DID resolver HTTP(S) endpoint:
We could potentially allow query components on both the
input DID URL and input service endpoint URL, if they both contain lists of
key/value parameters that can be merged.
Details of the Service Endpoint Construction algorithm have been discussed in April 2019
on the CCG mailing list, e.g., here
or here.
Instead of defining our own algorithm, we could potentially re-use the "Relative Resolution"
algorithm defined in [[RFC3986]].
DID resolution and DID URL dereferencing do not involve any authentication or authorization
functionality. Similar to DNS resolution, anybody can perform the process, without requiring any credentials
or non-public knowledge.
Explain that DIDs are not necessarily globally resolvable, such as pairwise or N-wise
"peer" DIDs.
See [[RFC3339]]:
URIs have a global scope and are interpreted consistently regardless of context, though the
result of that interpretation may be in relation to the end-user's context.
An advanced idea is that the result of DID resolution could be contextual or depend on policies,
see this comment.
A related topic is whether (parts of) DID document could be encrypted, e.g.,
w3c/did-core/issues/25. Also see the use
of the fragment in the IPID DID method.
Caching behavior can be controlled by configuration of the DID resolver,
by the noCache resolution option, or by contents of the DID document
(e.g., a `cacheMaxTtl` field), or by a combination of these properties.
See corresponding open issue.
Perhaps we can re-use caching mechanisms of other protocols such as HTTP.
The use of the versionId DID parameter is specific to the DID method.
Its possible values may include sequential numbers, random UUIDs, content hashes, etc..
DID document metadata MAY contain a versionId
property that changes with each Update operation that is performed
on a DID document.
There is discussion on the relationship between DID resolution and
resolution of non-DID identifiers such as domain names, HTTP URIs, or e-mail addresses. This includes the
questions how DIDs can be discovered from non-DID identifiers, and how links between identifiers can
be verifiable.
DID Method Governance
Describe which methods a DID resolver should support, and potential implications.
Future Work
This section lists additional DID URL dereferencing features that are under discussion and
have not yet been incorporated into the algorithm.
Redirect
A service endpoint may have
a serviceEndpoint property with a value that is itself
a DID. This is interpreted as a "DID redirect" from the input DID to another. In this case, a "child"
DID resolution process can be launched to get to a "final" service endpoint.
The follow-redirect resolution option can be supplied by a client as a hint to
instruct whether redirects should be followed. This resolution option is OPTIONAL.
See corresponding open issue.
DID redirects could not only apply to a single service endpoint, but
to an entire DID document, therefore enabling portability use cases.