Introduction
In streamlining operations and reacting to increasing expectations of market transparency and traceability, global supply chains are undergoing continuous digital transformation. At the same time, the surfaces exposed to cyber attacks are increasing. These vulnerabilities of critical society infrastructure are recognized by governments around the world, clearly described in this US Presidential Order:
The private sector must adapt to the continuously changing threat environment, ensure its products are built and operate
securely, and partner with governments to foster a more secure cyberspace. In the end, the trust we place in
our digital infrastructure should be proportional to [the trustworthiness and transparency of that infrastructure, and] to the
consequences [that may be incurred] if that trust is misplaced.
Source:
https://www.whitehouse.gov/briefing-room/presidential-actions/2021/05/12/executive-order-on-improving-the-nations-cybersecurity/
Similar recognition is seen in this Digital Strategy statement from the European Commission:
The digital transformation of society [...] has expanded the threat landscape and is
bringing about new challenges, which require adapted and innovative responses.
Now any disruption, even one initially confined to one entity or one sector, can have [more broad, cascading effects],
potentially resulting in far-reaching and long-lasting negative impacts in the delivery of services across the whole
internal market.
Source:
https://digital-strategy.ec.europa.eu/en/library/proposal-directive-measures-high-common-level-cybersecurity-across-union
The goal of this specification is to provide a path towards a secure digitized global supply chain. It does so by leveraging modern cryptography and web technology standards like the Verifiable Credential Data Model (VCDM), JSON for Linked Data (JSON-LD), and Decentralized Identifiers (DIDs).
Supply Chain Digitization
While digitization has revolutionized other industries with decades of value, supply chain industries have been slow and fragmented in their digital transformation journey. The sheer number and variety of supply chain actors makes technological advances incredibly difficult. For example, physical paper, manual processing, and outdated technologies still support the vast majority of supply chain information flows. Paper processing costs the supply chain industry upwards of $3 billion every year (not counting the additional costs of paper, ink, and printing) (see "When Will Supply Chains Finally Move on From Paper?"). The resulting data silos and blind spots throughout the supply chain have created a crisis that enterprises and regulators can no longer ignore. This problem is made worse by the coordination challenges inherent in increasingly global supply chains.
As long as semantic standards depend on manual adoption and complex implementations, the impacts of these investments are limited and delayed. Semantic standards and code lists are being rigorously managed by various standards organizations. However, language barriers and differing contexts between standards is a major source of imprecision and errors. The fragmentary environment around different standard types, applications, and governing bodies only adds to the complexity involved in adoption and integration of standards.
The identity of supply chain actors is another problem resulting in costs and errors. While nations and platforms have established digital identity regimes within their boundaries, no useful global identity scheme has emerged or been adopted. Public policy, borders, and commercial obstacles create large barriers for a global centralized model to be adopted. The result is that most businesses need to invest heavily in IT infrastructure and middleware data mapping tools to be integrated with their trading partners. In fact, digitizing a major supply chain will cost tens of millions of dollars at the current pace and will be a 3-to-5 year transformation effort in the future (see "A Simpler Way to Modernize Your Supply Chain"). Today, most enterprises only have 20% visibility into their supply chains when they need about 70% to 90% visibility to properly monitor their investments (see "In 2020, Supply-Chain Digitization Is No Longer Optional"). This means a heavy investment of capital is required to achieve this visibility, which results in de-facto vendor software lock-in.
Establishing Trust
Trust and efficiency are fundamental to supply chains and global trade. Supply chains are a network of economically connected and collaborative stakeholders that includes shippers, carriers, importers, regulators, and other key actors. Traditionally, trust is established in the supply chain by analogue signed contracts, physical meetings, phone calls, faxes, and regular audits that prove credibility of the engaging parties and compliance with relevant regulation. Digitization efforts in the sphere of “contractual trust” have been limited by challenges like altering digital data such as PDFs, which is both easy to do and difficult to detect. Some noteworthy steps have been taken to address this such as encrypted communication channels like HTTP-over-TLS (a/k/a HTTPS) and commercial digital signature platforms (i.e. Docusign). However, a trusted channel does not prevent data alteration by either party and globally scaling a proprietary platform is expensive and comes with political and practical implications.
This landscape has changed with the advent of the VC standard. This standard makes digital contractual trust accessible and affordable for anyone on the planet. VCs work by applying existing cryptographic standards (particularly modern curve-based digital signature algorithms) to business data that is typically exchanged over APIs or XML. The VC specification provides a data model for how data paired with a cryptographic signature should be represented in a data file. The data itself can be anything; it can describe a shipment, an organization, a product, an agreement, etc. The cryptographic signature ensures that anyone with the VC can verify that the data is how the issuer intended it to be. In other words, the VC standard enables the use of cryptographic standards and provides the verifier a sense of trust when presented with the data file from the issuer. The implications of this technology for global supply chains are far-reaching.
However, there remains a great deal of untapped potential from VCs. Trust can be established remotely and fully automated provided that suitable claims are presented and issued by a trustworthy third party such as an existing business partner, a commercial agent, or a government. "Chains of trust" can be established by linking back through relevant claims to a known trust anchor. As you can see, VCs have a great deal of potential in the future of supply chain technology.
Linked Semantics
Supply chain organizations use different words to say the same thing. For example, “Shipper” and “Consignor” are used interchangeably in shipping. Ensuring precise communication across supply chain participants given these varying vocabularies is challenging. For example, standards bodies govern semantic models with term definitions, APIs for common use cases, and code lists in an attempt to avoid ambiguity. The traditional challenge for these technical publications has been the human element: reading the spec, interpreting the API attribute name, or skimming through the code lists. This labor is required because the data sender and the data receiver have to establish the same understanding. This results in effort and IT costs for both the sender and receiver to ensure they’re communicating unambiguously.
Linked Data addresses this problem by letting computers establish semantic meaning. Leveraging how the web works, Linked Data explicitly ties terms to a precise Uniform Resource Identifier (URI). Much like a URL pointing at a specific website, a URI defines a specific term. Thus, when the data sender defines a term by pointing at a URI, no interpretation is needed and a computer can automatically understand it. Beyond the obvious benefit of establishing shared understanding, integrating Linked Data is simpler and more cost-effective than data interpretation and mapping.
Linked Data is not new. It drives internet indexing and search engines. This traceability-vocab specification simply introduces this technology for use in the supply chain industry. All of the schemas which define the data content of Verifiable Credentials are constructed with explicit pointers to the most relevant URIs of the terms used. Existing term definitions, which are available in online vocabularies, can be used to construct the Verifiable Credential schemas.
Global Identifiers
A final important part of modernizing the digital supply chain is targeting the problem of identification. The difficulty of scaling centralized solutions has led to the emergence of Decentralized Identifiers (DIDs). DIDs rely on cryptography to prove that you are in control of a given identity. A variety of different types of DIDs exist and apply to different use-cases, like short-term DIDs or long-term, enterprise, security-grade DIDs. A DID is trustless, meaning that anyone can make and control a DID at any time. The value and credibility of a DID comes from its relationship with credentials that are tied to it. These credentials are typically issued by third-party organizations and/or governments.
While the identification of supply chain parties is a major identity problem, DIDs also provide value in other contexts. DIDs can be used to represent products, shipments, contractual agreements, or anything else in the supply chain that would benefit from the properties of DIDs. When paired with DIDs representing supply chain actors, DIDs that represent supply chain products or shipments stand to offer an ever more granular snapshot of the supply chain.
Note that the traceability-vocab's use of Decentralized Identifiers is limited to example uses. Traditional means of identification can also be used, but use of DIDs is encouraged to ensure that actual control of an identity can be proven.
Technology Summary
This section describes the emerging technology standards of Verifiable Credentials, Linked Data, and Decentralized Identifiers with a real-world supply chain use case.
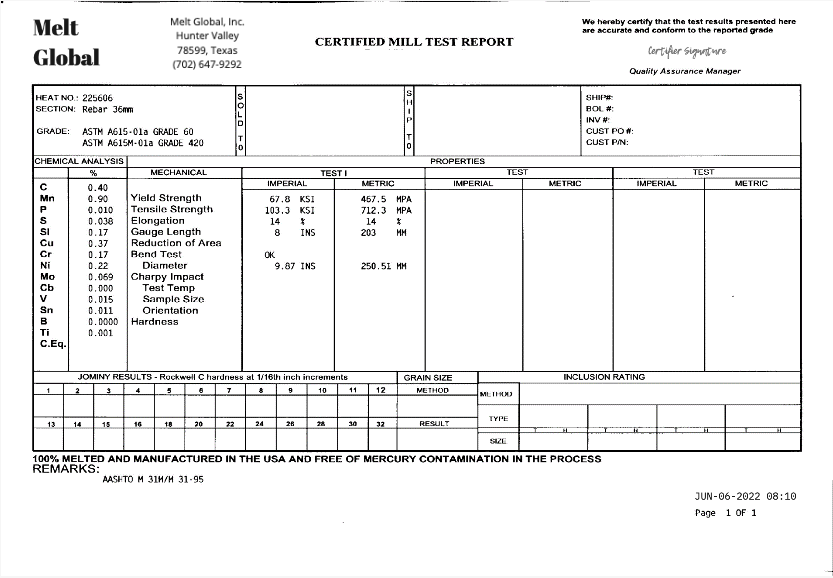
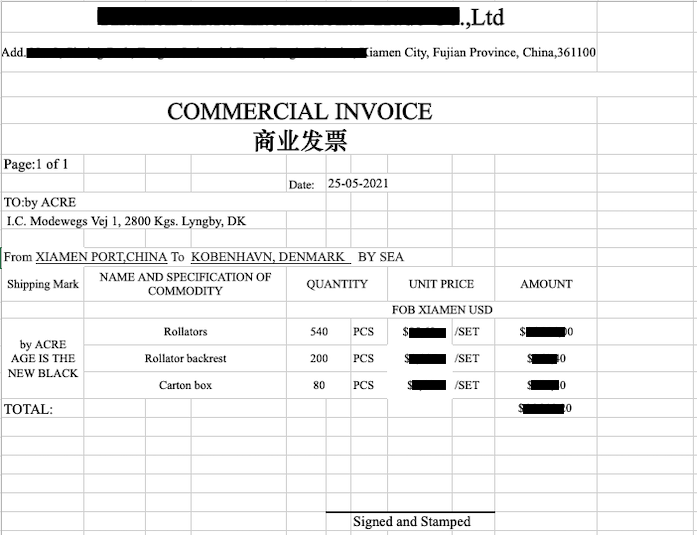
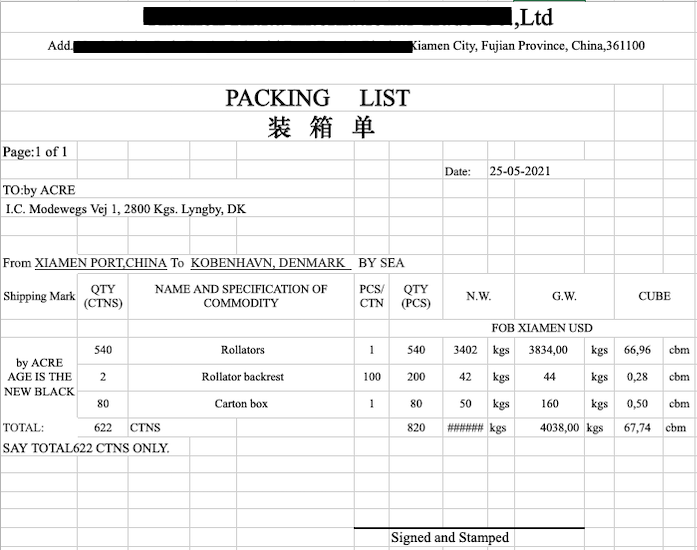
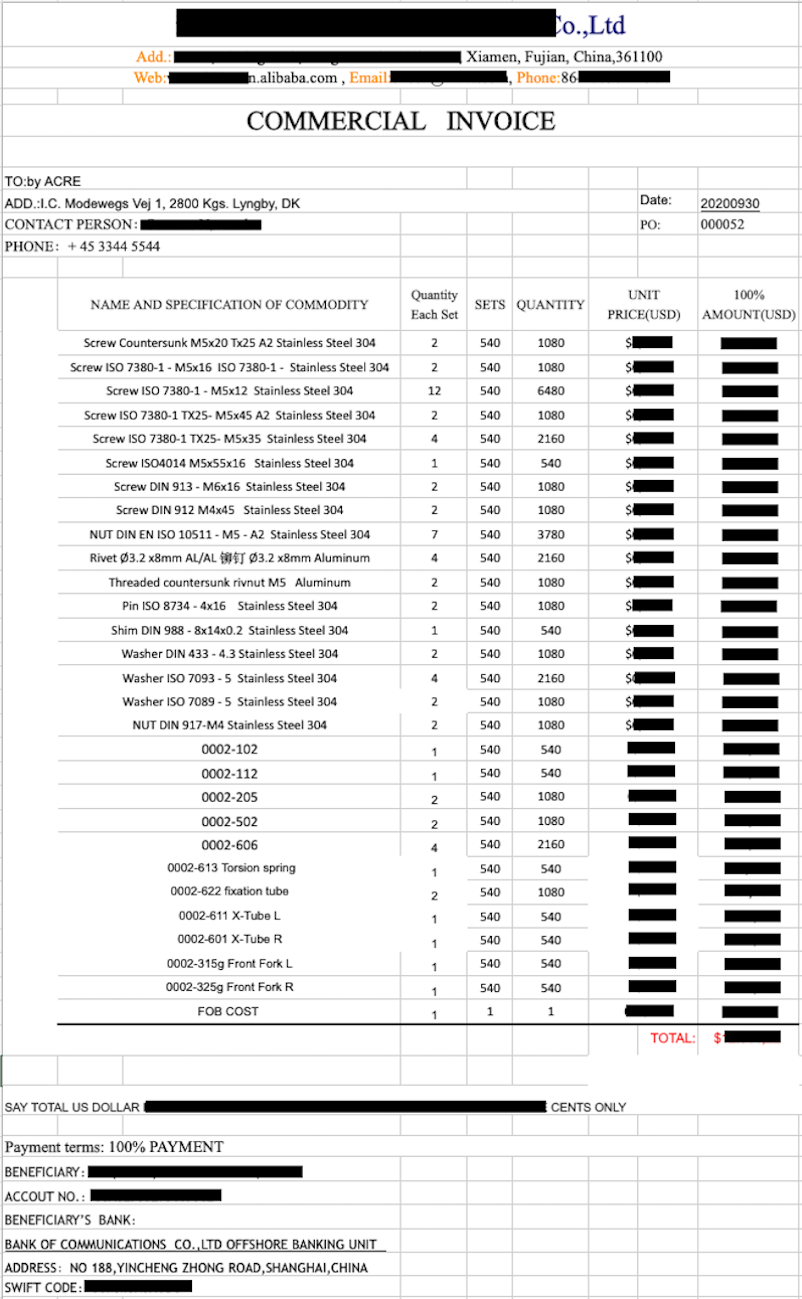
The Commercial Invoice is a critical supply chain document that is essential to Customs who use it for duty determination and other tasks. This document includes data such as the description of the goods, where the goods are being shipped to and from, and the value of the goods. This document is supplied by the shipper.
The Commercial Invoice document is typically exchanged via PDF, email, or EDI. With the use of Verifiable Credential technology, we are able to digitize a Commercial Invoice into a verifiable Commercial Invoice credential. Each data point on the Commercial Invoice VC is mapped to a semantic model for common definition using Linked Data. For example, the “Consignee” field or the “Shipper” field on the Commercial Invoice are defined unambiguously to precise URIs. This promotes a singular, common definition of the data labels so that organizations have a shared understanding.
In addition, certain data points on the Commercial Invoice are used to identify an organization. For example, the “Consignee” field identifies the receiver of the goods and the “Shipper” field identifies the shipper of the goods. In this example, both the consignee and shipper would be organizations. Using a Decentralized Identifier (DID), for example, the consignee organization can self-authenticate as the receiver of the goods.
The Shipper’s Decentralized Identifier is included as the Verifiable Credential issuer, binding the claims on the Commercial Invoice back to the Shipper. Cryptographic traceability of the Commercial Invoice is thus established from the Shipper to the Consignee. Anyone presented with the Commercial Invoice can verify that it originates from the Shipper and is targeted to the Consignee.
This example portrays a specific use case with a Commercial Invoice and shows how Verifiable Credentials, Linked Data, and Decentralized Identifiers apply. We apply these technologies to common trade documents to further digitize documents and promote trust throughout the entire supply chain.
Vocabulary
Generally, this vocabulary may be looked at as a set of common objects that are shared across multiple business verticals, and vertical or use case specific items that apply to one or more specific commodities or market segments. A primary goal of this specification is to standardize the creation of Verifiable Credentials from standardized JSON-LD which is itself created from JSON Schema definitions as would normally be passed of REST and other APIs. This promotes code re-use and establishes a pattern for the creation of JSON-LD and related Verifiable Credentials derived from those JSON-LD objects in a manner that is friendly to code and API development as well as to promote better interoperability between vendors who serve common or related markets.
The Vocabulary section covers each vocabulary item, its properties, other attributes, and provides and example Verifiable Credential for each item.
This repository has primary contributors from four main market segments,
and has subject matter experts from those market segments delegated as
leads for objects related to vocabulary items for each segment.
These subject matter leads help identify common elements across
verticals as well as in assessing contributions of new objects to the
vocabulary.
| Market Segment | Subject Matter Expert | Contact |
| Agriculture | Michael Prorock | mprorock@mesur.io |
| E-Commerce | Nis Jespersen | nis@transmute.industries |
| Oil and Gas | Mahmoud Alkhraishi | mahmoud@mavennet.com |
| Software Supply Chain | Benjamin Collins | benjamin@transmute.industries |
| Steel and Metals | Orie Steele | orie@transmute.industries |
Vocabulary Linkage
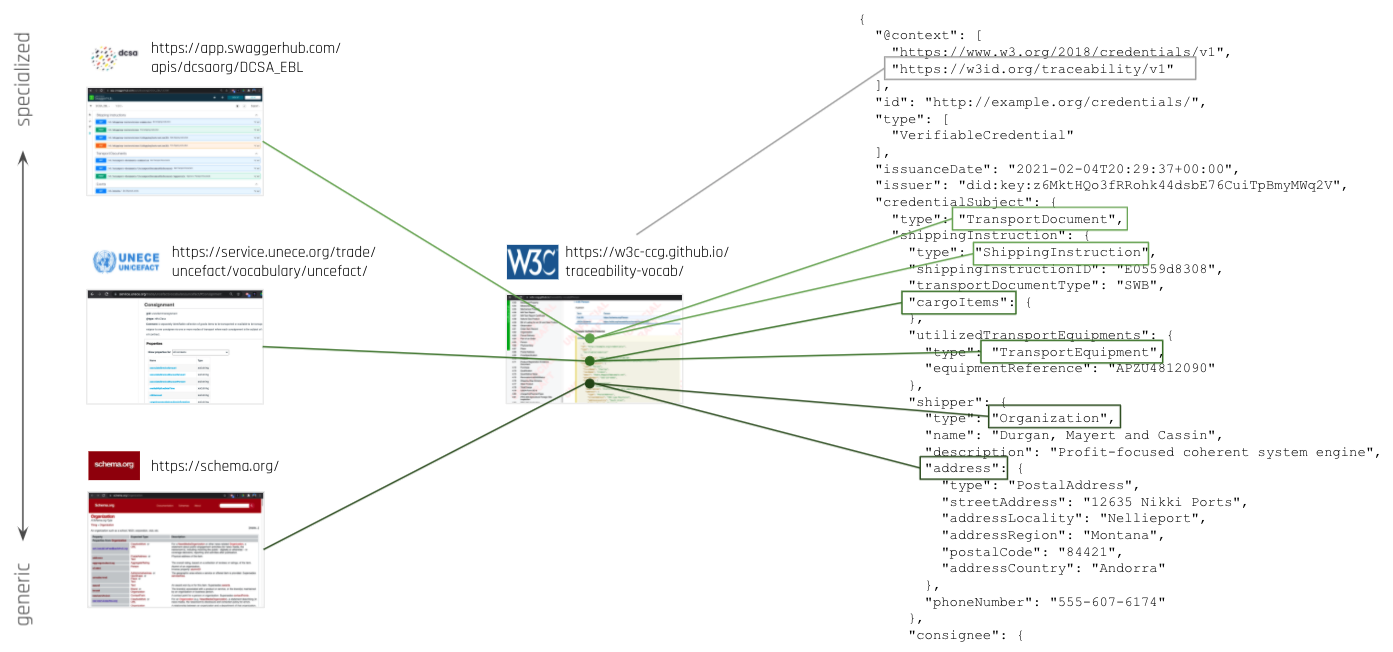
The traceability-vocab ensures that coherent sets of use case-specific schemas, blended together with corresponding resolvable @context data, point all the schemas' terms to their defining URIs. These URIs will generally point at existing, established vocabularies. Only when no applicable vocabularies can be found are terms defined as part of the traceability-vocab spec; these are considered exceptional cases.
In determining the most applicable vocabulary for a particular term, the most generic and widely adopted vocabulary is chosen. For example, a common term defined in schema.org will be chosen over a similar term defined in a industry-specific vocabulary. This is to ensure the broadest possible interoperability, within and beyond supply chain.
Open API
This vocabulary can also be viewed as an Open API Specification.
See w3id.org/traceability/interoperability for REST API and interoperability tests associated with this vocabulary.
Undefined Terms
This vocabulary uses
'@vocab': 'https://www.w3.org/ns/credentials/issuer-dependent#'
to disable JSON-LD related errors associated with Verifiable
Credentials, issued about terms that have not yet been added here.
Issuers are advised to review the JSON-LD and all associated terms before issuing verifiable credentials.